【製造業ベンチャーでソフトウェア開発と業務効率化をした話】シリーズ
「ソフトウェアによる効率化が製造業のベンチャーでも欠かせない」という思いから、FPC 製造のためのソフトウェアを自社開発してきた中で得られた成果そして苦労したところ良かったところなどの体験談を紹介していきたいと思います。
はじめに
このシリーズではこれまでソフトウェアを開発することでどれだけ綺麗に業務が効率化されてきたか、という非常に理想的なエピソードを書いてきました。しかし実際にはそれほど綺麗に問題が解決されることはなく、「ソフトウェアを開発したけど使ってもらえない」とか「そもそも根本的に何が問題なのかよくわかってない」という状況で、何度もソフトウェアの目的や使い方を説明したり工場に聞き取りに行き改善に一緒に取り組んだりすることで徐々に効率化されることが普通です。
この記事ではそのような「泥臭い」仕事を紹介することで、ソフトウェアを書くこと以外の仕事の重要さも伝えていけたらと思っています。
問題意識と作業の流れ
ありがたいことにエレファンテックでは製造量が増え続けていて、その結果、生産状況の管理・把握が以前より難しくなってきています。それらの問題の一つとしてリードタイムが正確に分からなくなってきたという問題がありました。
リードタイム(ここでは注文〜発送の時間とします)は、納期の見積もりにも生産の予定を立てる上でも必要な、製造業における最も基本的なデータです。リードタイムを正確に計測することと短くしていくことを目標に、工程ごとのリードタイムの調査に取り組みました。
実際の作業は次のような流れで行いました。
- 現状の分析
- 課題発見のためのデータ探索
- 「聞き取り→改善→データ確認」の繰り返し
まずは、そもそも生産管理ソフトが現在どのような仕組みになっていてどう運用されているかを簡単な聞き取りをしたりソフトウェアを調べたりすることで現状を分析しました。次に現在実際に取得されているデータを確認し探索することで課題を見つけ、それからその課題の解決に取り組みました。
現状の分析
リードタイムの調査を始める前から調査の妨げとなるような問題がいくつか想定されていました。
データの信頼性
リードタイムを調べる基本的なデータは「どの基板がどの工程をいつ通過したか」というデータになります。エレファンテックでは基板を複数並べたシートの単位で製造をしているため、シート・工程毎にデータを登録しています。製造装置を全てカスタマイズしている訳ではないので、全てを自動で記録するということはできておらず、手動で登録している工程も多くあります。そのため登録されたデータの質は必ずしも期待できるものではないのではと予想していました。
ソフトの未対応
内製している生産管理システムの更新が製造側の変更に追いついていないことが原因で、そもそも登録できてない工程や、作業の終了時刻は記録しているものの開始時刻は記録していない工程があります。
可視化
登録されているデータを表で確認することはできるようになっていますが、グラフで可視化をしたり集計して何か統計的なデータを出すということはされていませんでした。そのため全貌を把握するにはまずデータを手作業で探索することが必要になると考えていました。
課題発見のためのデータ探索
次に、先の分析を念頭に、実際にどのような問題が起きているのかを調査するために、既存のデータを様々な角度から可視化して分析することにしました。
1. 工程リードタイムの可視化
まずはリードタイムの調査の第一歩として、工程毎のリードタイムをヒストグラムにしてみました。JupyterとPandasでヒストグラムを描いた際のスクリーンショットが下の画像です。(横軸が時間[分]で縦軸はシート数です)
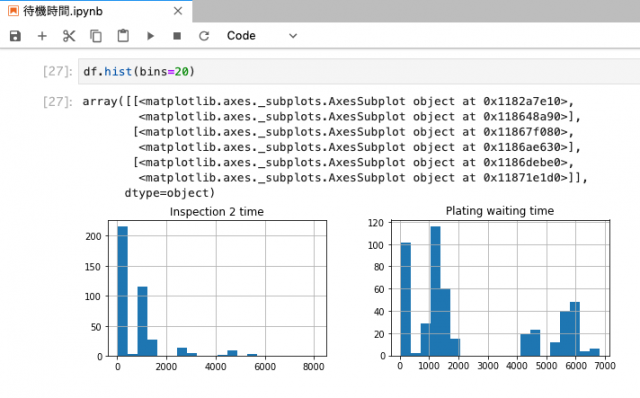
左が「検品2」と呼ばれている検品工程の待機時間+実作業時間で、右がめっき工程が始まるまでの待機時間のグラフです。上述のソフトの問題で検品2の待機時間と実作業時間を区別することがデータ上はできませんが、前提知識として実作業時間は数分であるということはわかっています。
とりあえず出してみたグラフなので軸の範囲やヒストグラムの階級数など修正すべき点は山ほどあるのですが、まずはこれでデータを眺めてみました。
まず分かることは、めっき工程の待機時間が非常に長いシートが結構あるということでした。横軸は分なので1440分で1日になりますが、3日(4320分)以上待機したままのシートが相当な数あります。
これは何が原因なのでしょうか?
少し調べた結果、4000分以上待機しているシートは3連休の間めっき工程で待機していたということが分かりました。待機時間は純粋な時刻の引き算で算出しているため、連休や週末、また製造していない夜などを時間に含めてしまうと非常に長く見えてしまいます。その他にも、社内の実験用に製造されたシートが他の注文が入ったために後回しにされていたというケースもありました。
ここから「待機時間を短くする」という一つめの目標ができました。また次の二点を学びとして次のステップに進むことにしました。
- 製造時間外を含めずに可視化をすべき
- 単純にデータを集計して可視化するだけでは、事情が様々なために最適化に進めない
2. シートごとに登録時刻の可視化
次に製品ごとに全シートの登録時刻をGoogle Chartsのタイムラインで一覧できるようにしました。工程ごとの時間を横軸に表示していて、また特定の工程が不要に長く見えないように製造時間外には横棒を表示しないようにしています。製品ごとに一覧することで、変なデータが入ってる場合にも固有の事情を思い出せて分かりやすくなりました。

このグラフを試しに生産管理システムに導入して使ってみたところ、まず分かったことは、そもそも登録時刻が全く正しくないことでした。同じシートが複数の工程でほぼ同時刻に登録されていたり、納品された日よりも後に工程登録されていたりしました。
これまで登録時刻のデータを何かに活用するということはなく正しいデータが入っているかどうか誰もチェックしていなかったので、正しいタイミングに登録していないこと自体は不思議ではないし、作業者を責めることでもありません。しかし単純に考えると作業したタイミングですぐ登録をするのが一番簡単なように思えるので、そうされてないということは恐らく何らかの解決すべき事情があることが想像できます。
この時点で「登録をリアルタイムにしてもらう」という二つめの小目標が定まりました。工程リードタイムを調べるための基礎的なデータである工程の作業時間を知る必要があり、その登録を正しくしてもらうために障害となっている問題を解決するという流れです。
次回に続く
工場のリードタイム(注文から発送までの時間)を調査することを最終的な目標に前編では現状の分析とデータを探索するところまでを書きました。後編は、データをいじって見つけた問題を解決するために「作業者への聞き取り・改善・データの再確認」という作業を繰り返し行った過程と、今回のプロジェクトで学んだことをまとめる予定です。
